Subsections
ベクトル(1次元行列)とリストは、一般の列である。
文字列(string)は、文字(character)のベクトルなので、列である。
map, concatenateやcoerceにおける結果の型を明記するためには、
クラスオブジェクトがsymbolにバインドされていないので、引用符なしで
cons, string, integer-vector, float-vectorなどのクラス名symbolを使う。
elt sequence pos [関数]
-
-
eltは、sequenceの中のpos番目の位置の値を得たり、(setfと
ともに)置いたりする最も一般的な関数である。
sequenceは、リストまたは任意のオブジェクト、bit, char, integer, floatの
ベクトルである。
eltは、多次元の行列に適用できない。
length sequence [関数]
-
-
sequenceの長さを返す。
ベクトルにおいて、lengthは一定の時間で終了する。
しかし、リスト型においては、長さに比例した時間がかかる。
lengthが、もし環状リストに適用されたとき、決して終了しない。
代わりにlist-lengthを使用すること。
もし、sequenceがfill-pointerを持つ行列ならば、
lengthは行列全体のサイズを返すのではなくfill-pointerを返す。
このような行列のサイズを知りたい場合には、array-total-sizeを
使用すること。
subseq sequence start &optional end [関数]
-
-
sequenceのstart番目から(end
 1)番目までをそっくりコピーした
列を作る。
endは、デフォルト値としてsequenceの長さをとる。
1)番目までをそっくりコピーした
列を作る。
endは、デフォルト値としてsequenceの長さをとる。
copy-seq sequence [関数]
-
-
sequenceのコピーした列を作る。
このコピーでは、sequenceのトップレベルの参照のみがコピーされる。
入れこリストのコピーにはcopy-treeを使い、
再帰参照を持つような列のコピーには
copy-objectを使うこと。
reverse sequence [関数]
-
-
sequenceの順番を逆にし、sequenceと同じ型の新しい列を
返す。
nreverse sequence [関数]
-
-
nreverseは、reverseの破壊(destructive)バージョンである。
reverseはメモリを確保するが、nreverseはしない。
concatenate result-type &rest sequences [関数]
-
-
全てのsequenceを連結させる。
それぞれのsequenceは、なにかの列型である。
appendと違って、最後の一つまで含めた全ての列がコピーされる。
result-typeは、cons,string,vector,float-vectorなどの
クラスである。
coerce sequence result-type [関数]
-
-
sequenceの型を変更する。
例えば、(coerce '(a b c) vector) = #(a b c)や
(coerce "ABC" cons) = (a b c)である。
result-type型の新しい列が作られ、
sequenceのそれぞれの要素はその列にコピーされる。
result-typeは、vector, integer-vector, float-vector, bit-vector, string, cons
またはそれらの1つを継承したユーザー定義クラス
のうちの1つである。
coerceは、sequenceの型がresult-typeと同一である場合、コピーをする。
map result-type function seq &rest more-seqs [関数]
-
-
functionは、seqとmore-seqsのそれぞれのN番目(
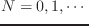 )の要素
からなるリストに
対して適用され、その結果はresult-typeの型の列に蓄積される。例えば、(map float-vector #'(lambda (x) (* x x)) (float-vector 1 2 3))のように書く。
)の要素
からなるリストに
対して適用され、その結果はresult-typeの型の列に蓄積される。例えば、(map float-vector #'(lambda (x) (* x x)) (float-vector 1 2 3))のように書く。
fill sequence item &key (start 0) (end (length sequence)) [関数]
-
-
sequenceのstart番目から(end1)番目まで、itemで満たす。
replace dest source &key start1 end1 start2 end2 [関数]
-
-
dest列の中のstart1からend1までの要素が、
source列の中のstart2からend2までの要素に置き換えられる。
start1とstart2のデフォルト値はゼロで、
end1とend2のデフォルト値はそれぞれの列の長さである。
もし片方の列がもう一方よりも長いならば、
endは短い列の長さに一致するように縮められる。
sort sequence compare &optional key [関数]
-
-
sequenceは、Unixのquick-sortサブルーチンを使って破壊的に(destructively)
にソートされる。
keyは、キーワードパラメータでなく、比較用のパラメータである。
同じ要素を持った列のソートをするときは十分気をつけること。
例えば、(sort '(1 1) #'>)は失敗する。なぜなら、1と1の比較は
どちらからでも失敗するからである。
この問題を避けるために、比較として#'
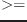 か#'
か#'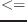 のような関数を用いる。
のような関数を用いる。
merge result-type seq1 seq2 pred &key (key #'identity) [関数]
-
-
2つの列seq1とseq2は、result-type型の1つの列に
合併され、それらの要素はpredに記述された比較を満足する。
merge-list list1 list2 pred key [関数]
-
-
2つのリストを合併させる。mergeと違って、一般列は引数として
許可されないが、merge-listはmergeより実行が速い
次の関数は、1つの基本関数と-ifや-if-notを後に付けた変形関数から成る。
基本形は、少なくともitemとsequenceの引数を持つ。
sequenceの中のそれぞれの要素とitemを比較し、
何かの処理をする。
例えば、インデックスを探したり、
現れる回数を数えたり、itemを削除したりなど。
変形関数は、predicateとsequenceの引数を持つ。
sequenceのそれぞれの要素にpredicateを適用し、
もしpredicateがnon-NILを返したとき(-if version)、
またはNILを返したとき(-if-not version)に何かをする。
position item seq &key start end test test-not key (count 1) [関数]
-
-
seqの中からitemと同一な要素を探し、
その要素の中で:count番目に現れた要素の
インデックスを返す。
その探索は、:start番目の要素から始め、それ以前の要素は無視する。
デフォルトの探索は、eqlで実行されるが、
testかtest-notパラメータで変更できる。
position-if predicate seq &key start end key [関数]
-
-
position-if-not predicate seq &key start end key [関数]
-
-
find item seq &key start end test test-not key (count 1) [関数]
-
-
seqの中のstart番目の要素から
:end番目の要素までの間で要素を探し、
その探された要素の内、:count番目の要素を返す。
その要素は、:testか:test-notに#'eql
以外のものが記述されていないなら、itemと同じものである。
find-if predicate seq &key start end key (count 1) [関数]
-
-
seqの要素の中でpredicateがnon-NILを返す要素の内、
:count番目の要素を返す。
find-if-not predicate seq &key start end key [関数]
-
-
count item seq &key start end test test-not key [関数]
-
-
seqの中の:start番目から:end番目までの要素にitemが
何回現れるか数える。
count-if predicate seq &key start end key [関数]
-
-
predicateがnon-NILを返すseq内の要素数を数える。
count-if-not predicate seq &key start end key [関数]
-
-
remove item seq &key start end test test-not key count [関数]
-
-
seqの中の:start番目から:end番目までの要素のなかで、
itemと同一の要素を探し、:count
(デフォルト値は∞)番目までの要素を削除した新しい列を作る。
もし、itemが一回のみ現れることが確定しているなら、
無意味な探索を避けるために、:count=1を指定すること。
remove-if predicate seq &key start end key count [関数]
-
-
remove-if-not predicate seq &key start end key count [関数]
-
-
remove-duplicates seq &key start end key test test-not count [関数]
-
-
seqの中から複数存在するitemを探し、その中の1つだけを残した新しい列を作る。
delete item seq &key start end test test-not key count [関数]
-
-
deleteは、seq自体を修正し、新しい列を作らないことを除いては、
remove同じである。
もし、itemが一回のみ現れることが確定しているなら、
無意味な探索を避けるために、:count=1を指定すること。
delete-if predicate seq &key start end key count [関数]
-
-
delete-if-not predicate seq &key start end key count [関数]
-
-
removeやdeleteの:countデフォルト値は、1,000,000である。
もし列が長く、削除したい要素が一回しか現れないときは、
:countを1と記述すべきである。
substitute newitem olditem seq &key start end test test-not key count [関数]
-
-
seqの中で:count番目に現れたolditemをnewitemに置き換えた
新しい列を返す。
デフォルトでは、全てのolditemを置き換える。
(substitute #\Space #\_ "Euslisp_euslisp") ;; => "Euslisp euslisp"
substitute-if newitem predicate seq &key start end key count [関数]
-
-
substitute-if-not newitem predicate seq &key start end key count [関数]
-
-
nsubstitute newitem olditem seq &key start end test test-not key count [関数]
-
-
seqの中でcount番目に現れたolditemをnewitemに置き換え、
元の列seqに返す。デフォルトでは、全てのolditemを置き換える。
nsubstitute-if newitem predicate seq &key start end key count [関数]
-
-
nsubstitute-if-not newitem predicate seq &key start end key count [関数]
-
-
listp object [関数]
-
-
オブジェクトがconsのインスタンスかもしくはNILならば、Tを返す。
consp object [関数]
-
-
(not (atom object))と同一である。(consp '())はNILである。
car list [関数]
-
-
listの最初の要素を返す。NILのcarはNILである。
atomのcarはエラーとなる。(car '(1 2 3)) = 1
cdr list [関数]
-
-
listの最初の要素を削除した残りのリストを返す。NILのcdrはNILである。
atomのcdrはエラーとなる。(cdr '(1 2 3)) = (2 3)
cadr list [関数]
-
-
(cadr list) = (car (cdr list))
cddr list [関数]
-
-
(cddr list) = (cdr (cdr list))
cdar list [関数]
-
-
(cdar list) = (cdr (car list))
caar list [関数]
-
-
(caar list) = (car (car list))
caddr list [関数]
-
-
(caddr list) = (car (cdr (cdr list)))
caadr list [関数]
-
-
(caadr list) = (car (car (cdr list)))
cadar list [関数]
-
-
(cadar list) = (car (cdr (car list)))
caaar list [関数]
-
-
(caaar list) = (car (car (car list)))
cdadr list [関数]
-
-
(cdadr list) = (cdr (car (cdr list)))
cdaar list [関数]
-
-
(cdaar list) = (cdr (car (car list)))
cdddr list [関数]
-
-
(cdddr list) = (cdr (cdr (cdr list)))
cddar list [関数]
-
-
(cddar list) = (cdr (cdr (car list)))
first list [関数]
-
-
listの最初の要素を取り出す。
second, third, fourth, fifth, sixth, seventh, eighthもまた定義されている。(first list) = (car list)
nth count list [関数]
-
-
list内のcount番目の要素を返す。
(nth 1 list)は、(second list)あるいは(elt list 1)と等価である。
nthcdr count list [関数]
-
-
listにcdrをcount回適用した後のリストを返す。
last list [関数]
-
-
listの最後の要素でなく、最後のconsを返す。
butlast list &optional (n 1) [関数]
-
-
listの最後からn個の要素を削除したリストを返す。
cons car cdr [関数]
-
-
carがcarでcdrがcdrであるような新しいconsを作る。
list &rest elements [関数]
-
-
makes a list of elements.
list* &rest elements [関数]
-
-
elementを要素とするリストを作る。しかし、最後の要素はconsされるため、
atomであってはならない。
例えば、(list* 1 2 3 '(4 5)) = (1 2 3 4 5)である。
list-length list [関数]
-
-
listの長さを返す。listは、環状リストでも良い。
make-list size &key initial-element [関数]
-
-
size長さで要素が全て:initial-elementのリストを作る。
rplaca cons a [関数]
-
-
consのcarをaに置き換える。
setfとcarの使用を推薦する。
(rplaca cons a) = (setf (car cons) a)
rplacd cons d [関数]
-
-
consのcdrをdに置き換える。
setfとcdrの使用を推薦する。
(rplacd cons d) = (setf (cdr cons) d)
memq item list [関数]
-
-
memberに似ている。しかしテストはいつもeqで行う。
member item list &key key (test #'eq) test-not [関数]
-
-
listの中から条件にあった要素を探す。
listの中からitemを探索し、:testの条件にあったものがなければNILを返す。
見つかったならば、それ以降をリストとして返す。この探索は、最上位のリストに対して
行なわれる。:testのデフォルトは#'eqである。
(member 'a '(g (a y) b a d g e a y))=(a d g e a y)
assq item alist [関数]
-
-
assoc item alist &key key (test #'eq) test-not [関数]
-
-
alistの要素のcarが:testの条件にあった最初のものを返す。
合わなければ、NILを返す。
:testのデフォルトは#'eqである。
(assoc '2 '((1 d t y)(2 g h t)(3 e x g))=(2 g h t)
rassoc item alist [関数]
-
-
cdrがitemに等しいalistのなかの最初の組を返す。
pairlis l1 l2 &optional alist [関数]
-
-
l1とl2の中の一致する要素を対にしたリストを作る。
もしalistが与えられたとき、
l1とl2から作られた対リストの最後に連結させる。
acons key val alist [関数]
-
-
alistにkey valの組を付け加える。
(cons (cons key val) alist)と同等である。
append &rest list [関数]
-
-
新しいリストを形成するためにlistを連結させる。
最後のリストを除いて、listのなかの全ての要素はコピーされる。
nconc &rest list [関数]
-
-
それぞれのlistの最後のcdrを置き換える事によって、listを
破壊的に(destructively)連結する。
subst new old tree [関数]
-
-
treeの中のすべてのoldをnewに置き換える。
flatten complex-list [関数]
-
-
atomやいろんな深さのリストを含んだcomplex-listを、
1つの線形リストに変換する。そのリストは、
complex-listの中のトップレベルに全ての要素を置く。
(flatten '(a (b (c d) e))) = (a b c d e)
push item place [マクロ]
-
-
placeにバインドされたスタック(リスト)にitemを置く。
pop stack [マクロ]
-
-
stackから最初の要素を削除し、それを返す。
もしstackが空(NIL)ならば、NILを返す。
pushnew item place &key test test-not key [マクロ]
-
-
もしitemがplaceのメンバーでないなら、
placeリストにitemを置く。
:test, :test-notと:key引数は、
member関数に送られる。
adjoin item list [関数]
-
-
もしitemがlistに含まれてないなら、listの最初に付け加える。
union list1 list2 &key (test #'eq) test-not (key #'identity) [関数]
-
-
2つのリストの和集合を返す。
subsetp list1 list2 &key (test #'eq) test-not (key #'identity) [関数]
-
-
list1がlist2の部分集合であること、すなわち、
list1のそれぞれの要素がlist2のメンバーであることをテストする。
intersection list1 list2 &key (test #'eq) test-not (key #'identity) [関数]
-
-
2つのリストlist1とlist2の積集合を返す。
set-difference list1 list2 &key (test #'eq) test-not (key #'identity) [関数]
-
-
list1にのみ含まれていて
list2に含まれていない要素からなるリストを返す。
set-exclusive-or list1 list2 &key (test #'eq) test-not (key #'identity) [関数]
-
-
list1およびlist2にのみ現れる要素からなるリストを返す。
list-insert item pos list [関数]
-
-
listのpos番目の要素としてitemを挿入する
(元のリストを変化させる)。
もしposがlistの長さより大きいなら、itemは最後に
nconcされる。
(list-insert 'x 2 '(a b c d)) = (a b x c d)
copy-tree tree [関数]
-
-
入れこリストであるtreeのコピーを返す。
しかし、環状参照はできない。環状リストは、
copy-objectでコピーできる。
実際に、copy-treeは(subst t t tree)と簡単に記述される。
mapc func arg-list &rest more-arg-lists [関数]
-
-
arg-listやmore-arg-listsそれぞれのN番目(
)の要素からなるリストに
funcを適用する。
適用結果は無視され、arg-listが返される。
mapcar func &rest arg-list [関数]
-
-
arg-listのそれぞれの要素にfuncをmapし、
その全ての結果のリストを作る。例えば、(mapcar #'(lambda (x) (* x x)) '(1 2 3))のように書く。
mapcarを使う前に、dolistを試すこと。
mapcan func arg-list &rest more-arg-lists [関数]
-
-
arg-listのそれぞれの要素にfuncをmapし、
nconcを用いてその全ての結果のリストを作る。
nconcはNILに対して何もしないため、
mapcanは、arg-listの要素にフィルタをかける(選択する)
のに合っている。
7次元以内の行列が許可されている。
1次元の行列は、ベクトルと呼ばれる。
ベクトルとリストは、列としてグループ化される。
もし、行列の要素がいろんな型であったとき、その行列は一般化されていると言う。
もし、行列がfill-pointerを持ってなく、他の行列で置き換えられなく、
拡張不可能であるなら、その行列は簡略化されたと言う。
全ての行列要素は、arefにより取り出すことができ、arefを用いてsetf
により設定することができる。
しかし、一次元ベクトルのために簡単で高速なアクセス関数がある。
svrefは一次元一般ベクトル、charとscharは
一次元文字ベクトル(文字列)、bitとsbitは
一次元ビットベクトルのための高速関数である。
これらの関数はコンパイルされたとき、
アクセスはin-lineを拡張し、型チェックと境界チェックなしに実行される。
ベクトルもまたオブジェクトであるため、
別のベクトルクラスを派生させることができる。
5種類の内部ベクトルクラスがある。
vector, string, float-vector, integer-vectorとbit-vectorである。
ベクトルの作成を容易にするために、make-array関数がある。
要素の型は、:integer, :bit, :character, :float, :foreign
かあるいはユーザーが定義したベクトルクラスの内の一つでなければならない。
:initial-elementと:initial-contentsのキーワード引数は、
行列の初期値を設定するために役に立つ。
array-rank-limit [定数]
-
-
7。行列の最大次元を示す。
array-dimension-limit [定数]
-
-
#x1fffffff。各次元の最大要素数を示す。
論理的な数であって、システムの物理メモリあるいは仮想メモリの大きさによって
制限される。
vectorp object [関数]
-
-
行列は1次元であってもベクトルではない。
objectがvector, integer-vector, float-vector, string, bit-vector
あるいはユーザーで定義したベクトルならTを返す。
vector &rest elements [関数]
-
-
elementsからなる一次元ベクトルを作る。
make-array [関数]
dims &key (element-type vector)
initial-contents
initial-element
fill-pointer
displaced-to
displaced-index-offset 0)
adjustable
-
- ベクトルか行列を作る。
dimsは、整数かリストである。
もしdimsが整数なら、一次元ベクトルが作られる。
svref vector pos [関数]
-
-
vectorのpos番目の要素を返す。
vectorは、一次元一般ベクトルでなければならない。
aref vector &rest indices [関数]
-
-
vectorのindicesによってインデックスされる要素を返す。
indicesは、整数であり、vectorの次元の数だけ指定する。
arefは、非効率的である。なぜなら、vectorの型に従うように
変更する必要があるためである。コンパイルコードの速度を改善する
ため、できるだけ型の宣言を与えるべきである。
vector-push val array [関数]
-
-
arrayのfill-pointer番目のスロットにvalを保管する。
arrayは、fill-pointerを持っていなければならない。
valが保管された後、
fill-pointerは、次の位置にポイントを1つ進められる。
もし、行列の境界よりも大きくなったとき、エラーが報告される。
vector-push-extend val array [関数]
-
-
arrayのfill-pointerが最後に到達したとき、自動的にarrayのサイズが
拡張されることを除いては、vector-pushと同じである。
arrayp obj [関数]
-
-
もしobjが行列またはベクトルのインスタンスであるならTを返す。
array-total-size array [関数]
-
-
arrayの要素数の合計を返す。
fill-pointer array [関数]
-
-
arrayのfill-pointerを返す。
fill-pointerを持っていなければNILを返す。
array-rank array [関数]
-
-
arrayの次元数を返す。
array-dimensions array [関数]
-
-
arrayの各次元の要素数をリストで返す。
array-dimension array axis [関数]
-
-
array-dimensionは、arrayのaxis
番目の次元を返す。axisはゼロから始まる。
bit bitvec index [関数]
-
-
bitvecのindex番目の要素を返す。
ビットベクトルの要素を変更するには、setfとbitを使用すること。
bit-and bits1 bits2 &optional result [関数]
-
-
bit-ior bits1 bits2 &optional result [関数]
-
-
bit-xor bits1 bits2 &optional result [関数]
-
-
bit-eqv bits1 bits2 &optional result [関数]
-
-
bit-nand bits1 bits2 &optional result [関数]
-
-
bit-nor bits1 bits2 &optional result [関数]
-
-
bit-not bits1 &optional result [関数]
-
-
同じ長さのbits1とbits2というビットベクトルにおいて、
それらのand, inclusive-or,
exclusive-or, 等価, not-and, not-orとnotがそれぞれ返される。
EusLispには、文字型がない。
文字は、integerによって表現されている。
ファイル名を現わす文字列を扱うためには、
9.6節に書かれているpathnameを使うこと。
digit-char-p ch [関数]
-
-
もしchが#
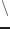 0〜#
9ならTを返す。
0〜#
9ならTを返す。
alpha-char-p ch [関数]
-
-
もしchが#
A〜#
Zまたは
#
a〜#
zなら、Tを返す。
upper-case-p ch [関数]
-
-
もしchが#
A〜#
Zなら、Tを返す。
lower-case-p ch [関数]
-
-
もしchが#
a〜#
zなら、Tを返す。
alphanumericp ch [関数]
-
-
もしchが#
0〜#
9、
#
A〜#
Zまたは
#
a〜#
zなら、Tを返す。
char-upcase ch [関数]
-
-
chを大文字に変換する。
char-downcase ch [関数]
-
-
chを小文字に変換する。
char string index [関数]
-
-
stringのindex番目の文字を返す。
schar string index [関数]
-
-
stringから文字を抜き出す。
stringの型が明確に解っていて、型チェックを要しないときのみ、schar
を使うこと。
stringp object [関数]
-
-
objectがバイト(256より小さい正の整数)のベクトルなら、Tを返す。
string-upcase str &key start end [関数]
-
-
strを大文字の文字列に変換して、新しい文字列を返す。
string-downcase str &key start end [関数]
-
-
strを小文字の文字列に変換して、新しい文字列を返す。
nstring-upcase str [関数]
-
-
strを大文字の文字列に変換し、元に置き換える。
nstring-downcase str &key start end [関数]
-
-
strを小文字の文字列に変換し、元に置き換える。
string= str1 str2 &key start1 end1 start2 end2 [関数]
-
-
もしstr1がstr2と等しいとき、Tを返す。
string=は、大文字・小文字を判別する。
string-equal str1 str2 &key start1 end1 start2 end2 [関数]
-
-
str1とstr2の等価性をテストする。
string-equalは、大文字・小文字を判別しない。
string object [関数]
-
-
objectの文字列表現を得る。
もしobjectが文字列なら、objectが返される。
もしobjectがsymbolなら、そのpnameがコピーされ、返される。
(equal (string 'a) (symbol-pname 'a))==Tであるが、
(eq (string 'a) (symbol-pname 'a))==NILである。
もしobjectが数値なら、それを文字列にしたものが返される
(これはCommon Lispと非互換である)。
もっと複雑なオブジェクトから文字列表現を得るためには、
最初の引数をNILにしたformat関数を用いること。
string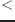 str1 str2 [関数]
str1 str2 [関数]
-
-
string str1 str2 [関数]
-
-
string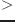 str1 str2 [関数]
str1 str2 [関数]
-
-
string str1 str2 [関数]
-
-
string-left-trim bag str [関数]
-
-
string-right-trim bag str [関数]
-
-
strは、左(右)から探索され、もしbagリスト内の文字を含んでいるなら、
その要素を削除する。
一旦bagに含まれない文字が見つかると、その後の探索は中止され、
strの残りが返される。
string-trim bag str [関数]
-
-
bagは、文字コードの列である。
両端にbagに書かれた文字を含まないstrのコピーが作られ、返される。
substringp sub string [関数]
-
-
sub文字列がstringに部分文字列として含まれるなら、Tを返す。
大文字・小文字を判別しない。
euslispで日本語を扱いたい時、文字コードはUTF-8である必要がある。
例えばconcatenateを用いると、リストの中の日本語を連結することが出来る。
ROSのトピックとして一つずつ取ってきた日本語を、連結することで一つのstring型の言葉に変換したい時などに便利である。
(concatenate string "け" "ん" "し" "ろ" "う")
→ "けんしろう"
最初から全ての文字がリストに入っていて、文字を連結したい時はこのようにすればよい。
(reduce #'(lambda (val1 val2) (concatenate string val1 val2)) (list "我" "輩" "は" "ピ" "ー" "ア" "ー" "ル" "ツ" "ー" "で" "あ" "る"))
→ "我輩はピーアールツーである"
coerceを用いて、次のように書くことも出来る。
(coerce (append (coerce "私はナオより" cons) (coerce "背が高い" cons)) string)
→ "私はナオより背が高い"
foreign-stringは、EusLispのヒープ外にあるバイトベクトルの1種である。
普通の文字列は、長さとバイトの列を持ったオブジェクトであるが、
foreign-stringは、長さと文字列本体のアドレスを持っている。
foreign-stringは文字列であるが、
いくつかの文字列および列に対する関数は適用できない。
length、aref、replace、subseqとcopy-seqだけが
foreign-stringを認識し、
その他の関数の適用はクラッシュの原因となる恐れがある。
foreign-stringは、/dev/a??d??(??は32あるいは16)の特殊ファイルで与えられる
I/O空間を参照することがある。
そのデバイスがバイトアクセスにのみ応答するI/O空間の一つに
割り当てられた場合、
replaceは、いつもバイト毎に要素をコピーする。
メモリのlarge chunkを連続的にアクセスしたとき、比較的に遅く動作する。。
make-foreign-string address length [関数]
-
-
addressの位置からlengthバイトの
foreign-stringのインスタンスを作る。
例えば、(make-foreign-string (unix:malloc 32) 32)は、
EusLispのヒープ外に位置する32バイトメモリを参照部分として作る。
hash-tableは、キーで連想される値を探すためのクラスである(assocでもできる)。
比較的大きな問題において、hash-tableはassocより良い性能を出す。
キーと値の組数が増加しても探索に要する時間は、一定のままである。
簡単に言うと、hash-tableは100以上の要素から探す場合に用い、
それより小さい場合はassocを用いるべきである。
hash-tableは、テーブルの要素数がrehash-sizeを越えたなら、自動的に拡張される。
デフォルトとして、テーブルの半分が満たされたとき拡張が起こるようになっている。
sxhash関数は、オブジェクトのメモリアドレスと無関係なハッシュ値を
返し、オブジェクトが等しい(equal)ときのハッシュ値はいつも同じである。
それで、hash-tableはデフォルトのハッシュ関数にsxhashを使用している
ので、再ロード可能である。
sxhashがロバストで安全な間は、
列やtreeの中のすべての要素を探索するため、比較的に遅い。
高速なハッシュのためには、アプリケーションにより他の特定のハッシュ関数を
選んだ方がよい。
ハッシュ関数を変えるためには、hash-tableに:hash-functionメッセージを
送信すれば良い。
簡単な場合、ハッシュ関数を#'sxhashから
#'sys:addressに変更すればよい。
EusLisp内のオブジェクトのアドレスは
決して変更されないため、#'sys:addressを設定することができる。
sxhash obj [関数]
-
-
objのハッシュ値を計算する。
equalな2つのオブジェクトでは、同じハッシュ値を生じること
が保証されている。
symbolなら、そのpnameに対するハッシュ値を返す。
numberなら、そのinteger表現を返す。
listなら、その要素全てのハッシュ値の合計が返される。
stringなら、それぞれの文字コードの合計をシフトしたものが返される。
その他どんなオブジェクトでも、sxhashはそれぞれのスロットのハッシュ値を
再帰的呼出しで計算し、それらの合計を返す。
make-hash-table &key (size 30) (test #'eq) (rehash-size 2.0) [関数]
-
-
hash-tableを作り、返す。
gethash key htab [関数]
-
-
htabの中からkeyと一致する値を得る。
gethashは、setfを組み合せることによりkeyに値を設定する
ことにも使用される。
hash-tableに新しい値が登録され、そのテーブルの埋まったスロットの数が
1/rehash-sizeを越えたとき、hash-tableは自動的に2倍の大きさに拡張される。
remhash key htab [関数]
-
-
htabの中からkeyで指定されたハッシュ登録を削除する。
maphash function htab [関数]
-
-
htabの要素全てをfunctionでmapする。
hash-table-p x [関数]
-
-
もしxがhash-tableクラスのインスタンスなら、Tを返す。
hash-table [クラス]
:super object
:slots (key value count
hash-function test-function
rehash-size empty deleted)
-
- hash-tableを定義する。
keyとvalueは大きさが等しい一次元ベクトルである。
countは、keyやvalueが埋まっている数である。
hash-functionのデフォルトはsxhashである。
test-functionのデフォルトはeqである。
emptyとdeletedは、keyベクトルのなかで空または削除された
数を示すsymbol(パッケージに収容されていない)である。
:hash-function newhash [メソッド]
-
-
このhash-tableのハッシュ関数をnewhashに変更する。
newhashは、1つの引数を持ち、integerを返す関数でなければならない。
newhashの1つの候補としてsys:addressがある。
queue はFIFO(first-in first-out)形式で要素の追加や検索を可能にするデー
タ構造である。
carがqueueの実体であり、このqueueのインスタンスをqとすると,その配列
は(print (car q))で表示できる。cdrに最も最近に追加された要素が確保される。
queue [クラス]
:super cons
:slots (car cdr)
-
- FIFO queueを定義する。
:init [メソッド]
-
-
queueを初期化する。
:enqueue val [メソッド]
-
-
このqueueにxを最新の要素として追加する。
:dequeue &optional (error-p nil) [メソッド]
-
-
このqueueの最も過去に追加された要素を返し、
queueから削除する。queueが空の場合,error-pが
NILでない場合はエラーを表示し、それ以外の場合はNILを返す。
:empty? [メソッド]
-
-
このqueueが空の場合、Tを返す。
:length [メソッド]
-
-
このqueueの長さを返す。
:trim s [メソッド]
-
-
このqueueの要素のうち古いものを破棄し、queueの長さをsとする。
:search item &optional (test #'equal) [メソッド]
-
-
このqueueにitemが存在するか調べる。もし無ければNILを返す。
:delete item &optional (test #'equal) (count 1) [メソッド]
-
-
このqueueからitemと同一の要素を探し、:count番目までの要素を削除する。
:first [メソッド]
-
-
このqueueの先頭の要素(最も過去に追加された要素)を返す。
:last [メソッド]
-
-
このqueueの最後の要素(最も最近に追加された要素)を返す。
This document was generated using the LaTeX2HTML translator on Sat Feb 5 14:36:44 JST 2022 from EusLisp version 138fb6ee Merge pull request #482 from k-okada/apply_dfsg_patch