Subsections
Vectors (one dimensional arrays) and lists are generic sequences.
A string is a sequence, since it is a vector of characters.
For the specification of result type in
map, concatenate and coerce,
use class name symbol, such as cons, string, integer-vector, float-vector,
etc. without quotes,
since the class object is bound to the symbol.
elt sequence pos [function]
-
-
elt is the most general function to get and put (in conjunction with
setf) value at the specific position pos in sequence.
Sequence may be a list, or a vector of arbitrary
object, bit, char, integer, or float.
Elt cannot be applied to a multi-dimensional array.
length sequence [function]
-
-
returns the length of sequence.
For vectors, length finishes in constant time, but
time proportional to the length is required for a list.
Length never terminates if sequence is a circular list.
Use list-length, instead.
If sequence is an array with a fill-pointer, length
returns the fill-pointer, not the entire size of the array entity.
Use array-total-size to know the entire size of those arrays.
subseq sequence start &optional end [function]
-
-
makes a copy of the subsequence from startth through (end-1)th inclusively
out of sequence.
end is defaulted to the length of sequence.
copy-seq sequence [function]
-
-
does shallow-copying of sequence, that is,
only the top-level references in sequence are copied.
Use copy-tree to copy a nested list,
or copy-object for deep-copying of a sequence
containing recursive references.
reverse sequence [function]
-
-
reverse the order of sequence and returns a new sequence of the
same type as sequence.
nreverse sequence [function]
-
-
Nreverse is the destructive version of reverse.
Nreverse does not allocate memory, while reverse does.
concatenate result-type &rest sequences [function]
-
-
concatenates all sequences.
Each sequence may be of any sequence type.
Unlike append, all the sequences including the last one are copied.
Result-type should be a class such as cons, string,
vector, float-vector etc.
coerce sequence result-type [function]
-
-
changes the type of sequence.
For examples, (coerce '(a b c) vector) = #(a b c) and
(coerce "ABC" cons) = (a b c).
A new sequence of type result-type is created, and each element of
sequence is copied to it.
result-type should be one of vector, integer-vector, float-vector,
bit-vector, string, cons or other user-defined classes inheriting
one of these.
Note that sequence is copied even if its type equals to result-type.
map result-type function seq &rest more-seqs [function]
-
-
function is applied to a list of arguments taken from seq
and more-seqs orderly, and the result is accumulated in a sequence
of type result-type. For example, you can write as follows: (map float-vector #'(lambda (x) (* x x)) (float-vector 1 2 3))
fill sequence item &key (start 0) (end (length sequence)) [function]
-
-
fills item from startth through (end-1)th in sequence.
replace dest source &key start1 end1 start2 end2 [function]
-
-
elements in dest sequence indexed between start1 and end1
are replaced with elements in source indexed between
start2 and end2.
start1 and start2 are defaulted to zero, and
end1 and end2 to the length of each sequence.
If the one of subsequences is longer than the other,
its end is truncated to match with the shorter subsequence.
sort sequence compare &optional key [function]
-
-
sequence is destructively sorted using Unix's quick-sort subroutine.
key is not a keyword parameter.
Be careful with the sorting of a sequence which have same elements.
For example, (sort '(1 1) #'>) fails because comparisons
between 1 and 1 in both direction fail.
To avoid this problem, use functions like #'
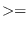 or #'
or #'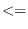 for comparison.
for comparison.
merge result-type seq1 seq2 pred &key (key #'identity) [function]
-
-
two sequences seq1 and seq2 are merged to form a single
sequence of result-type whose elements
satisfy the comparison specified by pred.
merge-list list1 list2 pred key [function]
-
-
merges two lists. Unlike merge no general sequences are allowed
for the arguments, but merge-list runs faster than merge.
Following functions consist of one basic function and its variants
suffixed by -if and -if-not.
The basic form takes at least the item and sequence arguments,
and compares item with each element in the sequence,
and do some processing,
such as finding the index,
counting the number of appearances, removing the item, etc.
Variant forms take predicate and sequence arguments,
applies the predicate to each element of sequence, and do something
if the predicate returns non-nil (-if version), or nil (-if-not version).
position item seq &key start end test test-not key (count 1) [function]
-
-
finds countth appearance of item in seq and returns
its index.
The search begins from the startth element, ignoring elements before it.
By default, the search is performed by eql, which can be altered
by the test or test-not parameter.
position-if predicate seq &key start end key [function]
-
-
position-if-not predicate seq &key start end key [function]
-
-
find item seq &key start end test test-not key (count 1) [function]
-
-
finds countth element between the startth element
and the endth element in seq.
The element found, which is eql to item if no test or
test-not other than #'eql is specified, is returned.
find-if predicate seq &key start end key (count 1) [function]
-
-
finds countth element in seq for which pred
returns non nil.
find-if-not predicate seq &key start end key [function]
-
-
count item seq &key start end test test-not key [function]
-
-
counts the number of items which appear between the startth element
and the endth element in seq.
count-if predicate seq &key start end key [function]
-
-
count the number of elements in seq for which pred returns
non nil.
count-if-not predicate seq &key start end key [function]
-
-
remove item seq &key start end test test-not key count [function]
-
-
creates a new sequence which has eliminated count (defaulted to infinity)
occurrences of of item(s) between the startth element
and the endth element in seq.
If you are sure that there is only one occurrence of item,
count=1 should be specified to avoid meaningless scan over the whole
sequence.
remove-if predicate seq &key start end key count [function]
-
-
remove-if-not predicate seq &key start end key count [function]
-
-
remove-duplicates seq &key start end key test test-not count [function]
-
-
removes duplicated items in seq and creates a new sequence.
delete item seq &key start end test test-not key count [function]
-
-
is same with remove except that delete modifies seq
destructively and does not create a new sequence.
If you are sure that there is only one occurrence of item,
count=1 should be specified to avoid meaningless scan over the whole
sequence.
delete-if predicate seq &key start end key count [function]
-
-
delete-if-not predicate seq &key start end key count [function]
-
-
count for removes and deletes is defaulted to 1,000,000.
If you have a long sequence and you want to delete an element which
appears only once, :count should be specified as 1.
substitute newitem olditem seq &key start end test test-not key count [function]
-
-
returns a new sequence which has
substituted the count occurrence(s)
of olditem in seq with newitem.
By default, all the olditems are substituted.
(substitute #\Space #\_ "Euslisp_euslisp") ;; => "Euslisp euslisp"
substitute-if newitem predicate seq &key start end key count [function]
-
-
substitute-if-not newitem predicate seq &key start end key count [function]
-
-
nsubstitute newitem olditem seq &key start end test test-not key count [function]
-
-
substitute the count occurrences of olditem in seq with newitem
destructively. By default, all the olditems are substituted.
nsubstitute-if newitem predicate seq &key start end key count [function]
-
-
nsubstitute-if-not newitem predicate seq &key start end key count [function]
-
-
listp object [function]
-
-
returns T if object is an instance of cons or NIL.
consp object [function]
-
-
equivalent to (not (atom object)). (consp '()) is nil.
car list [function]
-
-
returns the first element in list. car of NIL is NIL.
car of atom is error.
cdr list [function]
-
-
returns the list which removed the first element
of list. cdr of NIL is NIL.
cdr of atom is error.
cadr list [function]
-
-
(cadr list) = (car (cdr list))
cddr list [function]
-
-
(cddr list) = (cdr (cdr list))
cdar list [function]
-
-
(cdar list) = (cdr (car list))
caar list [function]
-
-
(caar list) = (car (car list))
caddr list [function]
-
-
(caddr list) = (car (cdr (cdr list)))
caadr list [function]
-
-
(caadr list) = (car (car (cdr list)))
cadar list [function]
-
-
(cadar list) = (car (cdr (car list)))
caaar list [function]
-
-
(caaar list) = (car (car (car list)))
cdadr list [function]
-
-
(cdadr list) = (cdr (car (cdr list)))
cdaar list [function]
-
-
(cdaar list) = (cdr (car (car list)))
cdddr list [function]
-
-
(cdddr list) = (cdr (cdr (cdr list)))
cddar list [function]
-
-
(cddar list) = (cdr (cdr (car list)))
first list [function]
-
-
retrieves the first element in list.
second, third, fourth, fifth, sixth, seventh, eighth are als
available.
nth count list [function]
-
-
returns the count-th element in list.
Note that (nth 1 list) is equivalent to (second list),
and to (elt list 1).
nthcdr count list [function]
-
-
applies cdr count times to list.
last list [function]
-
-
the last cons is returned, not the last element.
butlast list &optional (n 1) [function]
-
-
returns a list which does not contain the last n elements.
cons car cdr [function]
-
-
makes a new cons whose car is car and cdr is cdr.
list &rest elements [function]
-
-
makes a list of elements.
list* &rest elements [function]
-
-
makes a list of elements, but the last element is consed in cdr:
for example, (list* 1 2 3 '(4 5)) = (1 2 3 4 5).
list-length list [function]
-
-
returns the length of the list. List can be circular.
make-list size &key initial-element [function]
-
-
makes a list whose length is size and elements are initial-element.
rplaca cons a [function]
-
-
replace the car of cons with a.
Use of setf to car is recommended.
rplacd cons d [function]
-
-
replace the cdr of cons with d.
Use of setf to cdr is recommended.
memq item list [function]
-
-
resembles member, but test is always done by eq.
member item list &key key (test #'eq) test-not [function]
-
-
the list is searched for an element that satisfies the test.
If none is found, NIL is returned; otherwise, the tail of list beginning
with the first element that satisfied the test is returned. The list
is searched on the top level only.
assq item alist [function]
-
-
assoc item alist &key key (test #'eq) test-not [function]
-
-
searches the association list alist. The value returned is the
first pair in the alist such that the car of the pair satisfies
the test, or NIL if there is no such pair in the alist.
rassoc item alist [function]
-
-
returns the first pair in alist whose cdr is equal to item.
pairlis l1 l2 &optional alist [function]
-
-
makes a list of pairs consing corresponding elements in l1 and l2.
If alist is given, it is concatenated at the tail of the pair list
made from l1 and l2.
acons key val alist [function]
-
-
add the key val pair to alist, that is,
(cons (cons key val) alist).
append &rest list [function]
-
-
appends list to form a new list.
All the elements in list, except the last list, are copied.
nconc &rest list [function]
-
-
concatenates list destructively by replacing the last cdr of each
list.
subst new old tree [function]
-
-
substitutes every old in tree with new.
flatten complex-list [function]
-
-
Complex-list composed of atoms and lists of any depth
is transformed into a single level linear list which have all the elements
in complex-list at the top level.
For example, (flatten '(a (b (c d) e))) = (a b c d e)
push item place [macro]
-
-
pushes item into a stack (list) bound to place.
pop stack [macro]
-
-
removes the first item from stack and returns it.
If stack is empty (nil), nil is returned.
pushnew item place &key test test-not key [macro]
-
-
pushes item in the place list
if item is not a member of place.
The test, test-not and key arguments are
passed to the member function.
adjoin item list [function]
-
-
The item is added at the head of the list if it is not included
in the list.
union list1 list2 &key (test #'eq) test-not (key #'identity) [function]
-
-
returns union set of two lists.
subsetp list1 list2 &key (test #'eq) test-not (key #'identity) [function]
-
-
tests if list1 is a subset of list2, i.e. if each element
of list1 is a member of list2.
intersection list1 list2 &key (test #'eq) test-not (key #'identity) [function]
-
-
returns the intersection of two sets, list1 and list2.
set-difference list1 list2 &key (test #'eq) test-not (key #'identity) [function]
-
-
returns the list whose elements are only contained in list1
and not in list2.
set-exclusive-or list1 list2 &key (test #'eq) test-not (key #'identity) [function]
-
-
returns the list of elements that appear only either in list1 or list2.
list-insert item pos list [function]
-
-
insert item as the pos'th element in list destructively.
If pos is bigger than the length of list, item is
nconc'ed at the tail.
For example, (list-insert 'x 2 '(a b c d)) = (a b x c d)
copy-tree tree [function]
-
-
returns the copy of tree which may be a nested list
but cannot have circular reference. Circular lists can be copied by
copy-object.
Actually, copy-tree is simply coded as (subst t t tree).
mapc func arg-list &rest more-arg-lists [function]
-
-
applies func to a list of N-th elements in arg-list and each of
more-arg-lists.
The results of application are ignored and arg-list is returned.
mapcar func &rest arg-list [function]
-
-
maps func to each element of arg-list,
and makes a list from all the results. For example, you can write as follows: (mapcar #'(lambda (x) (* x x)) '(1 2 3)).
Before using mapcar, try dolist.
mapcan func arg-list &rest more-arg-lists [function]
-
-
maps func to each element of arg-list,
and makes a list from all the results by nconc.
Mapcan is suitable for filtering (selecting) elements
in arg-list, since nconc does nothing with NIL.
Up to seven dimensional arrays are allowed.
A one-dimensional array is called vector.
Vectors and lists are grouped as sequence.
If the elements of an array is of any type, the array is said to be general.
If an array does not have fill-pointer, is not displaced to
another array, or is adjustable, the array is said to be simple.
Every array element can be recalled by aref and set by setf in
conjunction with aref.
But for simple vectors, there are simpler and faster access functions:
svref for simple general vectors, char and schar for
simple character vectors (string), bit and sbit for
simple bit vectors. When these functions are compiled,
the access is expanded in-line and no type check and boundary check are
performed.
Since a vector is also an object,
it can be made by instantiating some vector-class.
There are five kinds of built-in vector-classes;
vector, string, float-vector, integer-vector and bit-vector.
In order to ease instantiation of vectors, the function make-array
is provided.
Element-type should be one of :integer, :bit, :character, :float, :foreign
or user-defined vector class.
:initial-element and :initial-contents key word arguments are
available to set initial values of the array you make.
array-rank-limit [constant]
-
-
7. Is the maximum array rank supported.
array-dimension-limit [constant]
-
-
#x1fffffff, logically, but stricter limit is imposed
by the physical or virtual memory size of the system.
vectorp object [function]
-
-
An array is not a vector even if it is one dimensional.
T is returned for vectors, integer-vectors, float-vectors, strings,
bit-vectors or other user-defined vectors.
vector &rest elements [function]
-
-
makes a simple vector from elements.
make-array [function]
dims &key (element-type vector)
initial-contents
initial-element
fill-pointer
displaced-to
(displaced-index-offset 0)
adjustable
-
- makes a vector or array.
dims is either an integer or a list.
If dims is an integer, a simple-vector is created.
svref vector pos [function]
-
-
returns posth element of vector.
Vector must be a simple general vector.
aref vector &rest indices [function]
-
-
returns the element indexed by indices.
Aref is not very efficient
because it needs to dispatch according to the type of vector.
Type declarations should be given to improve the speed of compiled code
whenever possible.
vector-push val array [function]
-
-
store val at the fill-pointerth slot in array.
array must have a fill-pointer.
After val is stored,
the fill-pointer is advanced by one to point to the next location.
If it exceeds the array boundary, an error is reported.
vector-push-extend val array [function]
-
-
Similar to vector-push except that
the size of the array is automatically extended
when array's fill-pointer reaches the end.
arrayp obj [function]
-
-
T if obj is an instance of array or vector.
array-total-size array [function]
-
-
returns the total number of elements of array.
fill-pointer array [function]
-
-
returns the fill-pointer of array.
Returns NIL if array does not have any fill-pointer.
array-rank array [function]
-
-
returns the rank of array.
array-dimensions array [function]
-
-
returns a list of array-dimensions.
array-dimension array axis [function]
-
-
Axis starts from 0. array-dimension returns the axisth
dimension of array.
bit bitvec index [function]
-
-
returns the indexth element of bitvec.
Use setf and bit to change an element of a bit-vector.
bit-and bits1 bits2 &optional result [function]
-
-
bit-ior bits1 bits2 &optional result [function]
-
-
bit-xor bits1 bits2 &optional result [function]
-
-
bit-eqv bits1 bits2 &optional result [function]
-
-
bit-nand bits1 bits2 &optional result [function]
-
-
bit-nor bits1 bits2 &optional result [function]
-
-
bit-not bits1 &optional result [function]
-
-
For bit vectors bits1 and bits2 of the same length,
their boolean and, inclusive-or,
exclusive-or, equivalence, not-and, not-or and not are returned, respectively.
There is no character type in EusLisp;
a character is represented by an integer.
In order to handle strings representing file names,
use pathnames described in 11.6.
digit-char-p ch [function]
-
-
T if ch is #
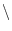 0 through #
9.
0 through #
9.
alpha-char-p ch [function]
-
-
T if ch is #
A through #
Z or
#
a through #
z.
upper-case-p ch [function]
-
-
T if ch is #
A through #
Z.
lower-case-p ch [function]
-
-
T if ch is #
a through #
z.
alphanumericp ch [function]
-
-
T if ch is #
0 through #
9,
#
A through #
Z
or #
a through #
z.
char-upcase ch [function]
-
-
convert the case of ch to upper.
char-downcase ch [function]
-
-
convert the case of ch to lower.
char string index [function]
-
-
returns indexth character in string.
schar string index [function]
-
-
extracts a character from string. Use schar only if the
type of string is definitely known and no type check is required.
stringp object [function]
-
-
returns T if object is a vector of bytes (integers less than 256).
string-upcase str &key start end [function]
-
-
converts str to upper case string and returns a new string.
string-downcase str &key start end [function]
-
-
converts str to lower case string and returns a new string.
nstring-upcase str [function]
-
-
converts str to upper case string destructively.
nstring-downcase str &key start end [function]
-
-
converts str to lower case string destructively.
string= str1 str2 &key start1 end1 start2 end2 [function]
-
-
T if str1 is equal to str2.
string= is case sensitive.
string-equal str1 str2 &key start1 end1 start2 end2 [function]
-
-
tests equality of str1 and str2.
string-equal is not case sensitive.
string object [function]
-
-
gets string notation of object. If object is a string, the object
is returned. If object is a symbol, its pname is copied and returned.
Note that (equal (string 'a) (symbol-pname 'a))==T, but
(eq (string 'a) (symbol-pname 'a))==NIL.
If object is number its string representation is returned
(this is incompatible with Common Lisp).
In order to get string representation for more complex objects,
use format with NIL in the first argument.
string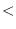 str1 str2 [function]
str1 str2 [function]
-
-
string str1 str2 [function]
-
-
string str1 str2 [function]
str1 str2 [function]
-
-
string str1 str2 [function]
-
-
string-left-trim bag str [function]
-
-
string-right-trim bag str [function]
-
-
str is scanned from the left(or right),
and its elements are removed if
it is included in the bag list.
Once a character other than the ones in the bag is found,
further scan is aborted and the rest of str
is returned.
string-trim bag str [function]
-
-
Bag is a sequence of character codes.
A new copy of str which does not contain characters specified in bag
in its both end is made and returned.
substringp sub string [function]
-
-
T if string sub is contained in string as a substring.
Not case sensitive.
A foreign-string is a kind of byte-vector whose entity is held somewhere
outside EusLisp's heap.
While a normal string is represented by a sequence of bytes and its length,
a foreign-string holds the length and the address of the string entity.
Although foreign-string is a string,
some string and sequence functions cannot be applicable.
Only length, aref, replace, subseq and copy-seq
recognize the foreign-string,
and application of other functions may cause a crash.
A foreign-string may refer to a part of I/O space usually
taken in /dev/a??d?? special file where ?? is either 32 or 16.
In case the device attached in one of these I/O space only responds
to byte access, replace always copies element byte by byte,
which is relatively slow when a large chunk of memory is accessed
consecutively.
make-foreign-string address length [function]
-
-
makes an instance of foreign-string located at address
and spanning for length bytes.
For example, (make-foreign-string (unix:malloc 32) 32)
makes a reference to a 32-byte memory located outside EusLisp's heap.
Hash-table is a class to search for the value associated with a key,
as accomplished by assoc.
For a relatively large problem,
hash-table performs better than assoc, since time required for searching remains constant even
the number of key-value pairs increases.
Roughly speaking, hash-table should be used in search spaces with
more than 100 elements, and assoc in smaller spaces.
Hash-tables automatically expands if the number of elements
in the table exceeds rehash-size.
By default, expansion occurs when a half of the table is filled.
sxhash function returns a hash value which is independent
of memory address of an object, and hash values for equal objects
are always the same.
So, hash tables can be re-loadable since they use sxhash as their default
hashing functions.
While sxhash is robust and safe,
it is relatively slow because it scans all the elements
in a sequence or a tree.
For faster hashing, you may choose another hash function appropriate
for your application.
To change the hash function, send :hash-function message
to the hash-table.
In simple cases, it is useful to change hash function from #'sxhash
to #'sys:address.
This is possible because the addresses of any objects
never change in a EusLisp process.
sxhash obj [function]
-
-
calculates the hash value for obj.
Two objects which are equal are guaranteed to yield
the same hash value.
For a symbol, hash value for its pname is returned.
For numbers, their integer representations are returned.
For a list, sum of hash values for all its elements is returned.
For a string, shifted sum of each character code is returned.
For any other objects, sxhash is recursively called to calculate
the hash value of each slot, and the sum of them is returned.
make-hash-table &key (size 30) (test #'eq) (rehash-size 2.0) [function]
-
-
creates a hash table and returns it.
gethash key htab [function]
-
-
gets the value that corresponds to key in htab.
Gethash is also used to set a value to key by combining with setf.
When a new entry is entered in a hash table, and the number of filled slots
in the table exceeds 1/rehash-size, then the hash table is automatically
expanded to twice larger size.
remhash key htab [function]
-
-
removes a hash entry designated by key in htab.
maphash function htab [function]
-
-
maps function to all the elements of htab.
hash-table-p x [function]
-
-
T if x is an instance of class hash-table.
hash-table [class]
:super object
:slots (key value count
hash-function test-function
rehash-size empty deleted)
-
- defines hash table.
Key and value are simple-vectors of the same size.
Count is the number of filled slots in key and value.
Hash-function is defaulted to sxhash and
test-function to eq.
Empty and deleted are uninterned symbols to indicate
slots are empty or deleted in the key vector.
:hash-function newhash [method]
-
-
changes the hash function of this hash table to newhash.
Newhash must be a function with one argument and returns an integer.
One of candidates for newhash is system:address.
A queue is a data structure that allows insertion and retrieval of data
in the FIFO manner, i.e. the first-in first-out order.
Since the queue class is defined by extending the cons class,
ordinary list functions can be applied to a queue.
For example, caar retrieves the next element to be dequeued,
and cadr gets the element that is queued most recently.
queue [class]
:super cons
:slots (car cdr)
-
- defines queue (FIFO) objects.
:init [method]
-
-
initializes the queue to have no elements.
:enqueue val [method]
-
-
puts val in the queue as the most recent element.
:dequeue &optional (error-p nil) [method]
-
-
retrieves the oldest value in the queue, and removes it of the queue.
If the queue is empty, it reports an error when error-p is non-nil,
or returns NIL otherwise.
:empty? [method]
-
-
returns T if the queue is empty.
:length [method]
-
-
returns the length of the queue.
:trim s [method]
-
-
discard old entries to keep the size of this queue to s.
:search item &optional (test #'equal) [method]
-
-
find element which is equal to item.
the search is performed by equal, which can be altered by test
:delete item &optional (test #'equal) (count 1) [method]
-
-
eliminate count occurrences of item in this queue.
:first [method]
-
-
returns the first entry (oldest value) of this queue.
:last [method]
-
-
returns tha last entry (newest value) of this queue.
This document was generated using the LaTeX2HTML translator on Sat Feb 5 14:36:57 JST 2022 from EusLisp version 138fb6ee Merge pull request #482 from k-okada/apply_dfsg_patch